MCP-сервер для UI-библиотеки: зачем, как и где хранить данные
- MCP
- VKUI
- AI
- Архитектура
AI-ассистенты вроде Cursor, Claude Desktop или Windsurf умеют писать код, но плохо знают конкретные библиотеки: путают пропсы, выдумывают несуществующие компоненты и предлагают устаревший API. Проблема в том, что модель оперирует данными из обучающей выборки, а документация библиотеки обновляется после каждого релиза. В этой статье расскажу, как я решил эту проблему для VKUI — сделал MCP-сервер, который подключает AI к актуальной документации.
Что такое MCP-сервер
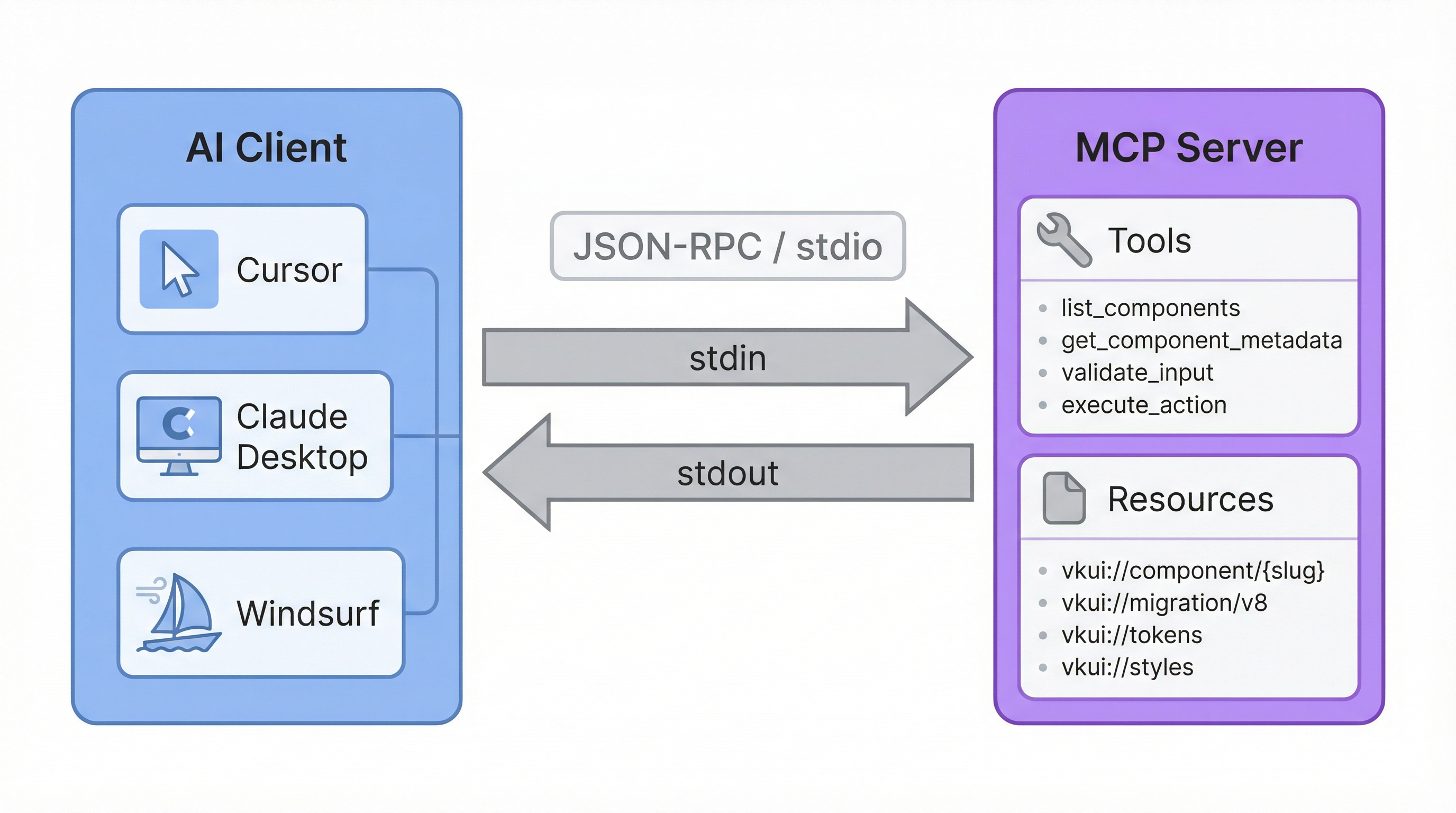
Model Context Protocol (MCP) — открытый протокол, придуманный в Anthropic, для подключения AI-приложений к внешним данным и инструментам. Идея простая: AI-клиент (Cursor, Claude Desktop и др.) общается с MCP-сервером по стандартному протоколу и получает доступ к данным, о которых ничего не знает из обучения.
MCP-сервер предоставляет две сущности:
- Инструменты (tools) — функции, которые клиент вызывает по запросу. Модель сама решает, когда вызвать тот или иной инструмент, на основе описания (
description) и входных параметров. Это как API-эндпоинты, но для AI. - Ресурсы (resources) — URI, по которым клиент читает контент без вызова инструментов. Ресурс можно подключить как контекст «из файла», модель видит его содержимое целиком.
Транспорт — stdio: клиент запускает MCP-сервер как дочерний процесс и общается с ним через stdin/stdout по JSON-RPC. Никаких HTTP-серверов, портов и CORS — просто процесс, который читает и пишет в стандартные потоки.
Зачем MCP-сервер для UI-библиотеки
VKUI — крупная библиотека компонентов: десятки компонентов, хуки, сложные пропсы, кастомные паттерны. При работе с такой библиотекой через AI-ассистент возникают типичные проблемы:
-
Галлюцинации по API. Модель «помнит» устаревшую версию API или вовсе выдумывает пропсы. Например, в v8 VKUI проп
onCloseуActionSheetпереименован вonClosed, аgetRefуInputпереехал вslotProps.input.getRootRef. Модель, обученная на старом коде, об этом не знает. -
Нет примеров. Даже если модель правильно подобрала компонент, без живых примеров из документации она конструирует код «по наитию», пропуская специфику (обёртки, провайдеры, обязательные пропсы).
-
Миграция между версиями. При обновлении мажорной версии десятки компонентов меняют API. Ручной разбор миграционного гайда и правка каждого файла — рутина, которую AI мог бы автоматизировать, если бы знал «до» и «после».
Всё это решается тем, что MCP-сервер даёт модели доступ к актуальной документации: списку компонентов и хуков, их пропсам, примерам кода и рекомендациям по миграции. Модель не гадает — она запрашивает данные, когда они нужны.
Это актуально не только для VKUI, но и для любой UI-библиотеки, дизайн-системы или фреймворка с обширным API: Material UI, Ant Design, Radix и других. Чем больше компонентов и чем чаще обновляется API, тем больше пользы от MCP-сервера.
Инструменты и ресурсы
Инструменты
Сервер предоставляет восемь инструментов, разбитых на четыре группы.
Компоненты:
| Инструмент | Описание |
|---|---|
list_components | Список всех компонентов (имя, slug, описание, количество примеров) |
get_component_metadata | Карточка компонента: описание, пропсы с типами, примеры с кодом |
Хуки:
| Инструмент | Описание |
|---|---|
list_hooks | Список всех хуков |
get_hook_metadata | Карточка хука: описание, параметры, примеры |
Примеры кода:
| Инструмент | Описание |
|---|---|
list_examples | Список примеров (с опциональной фильтрацией по компоненту) |
get_example | Код конкретного примера по id |
Миграция на v8:
| Инструмент | Описание |
|---|---|
list_migration_targets | Список компонентов и хуков, для которых есть рекомендации по миграции |
get_migration_target | Фрагменты кода «до» и «после» для конкретного компонента/хука |
Ресурсы
Помимо инструментов, сервер предоставляет ресурсы — данные, которые клиент может подключить как контекст:
| URI | Описание |
|---|---|
vkui://migration/v8 | Обзор всех целей миграции на v8 |
vkui://component/{slug} | Карточка компонента по slug |
vkui://migration/{name} | Рекомендации по миграции конкретного компонента |
Ресурсы поддерживают автодополнение: при вводе slug или имени клиент подсказывает доступные варианты.
Почему именно такой набор инструментов
Набор инструментов определяется сценариями использования. Я выделил три основных:
Сценарий 1: «Помоги написать код с VKUI»
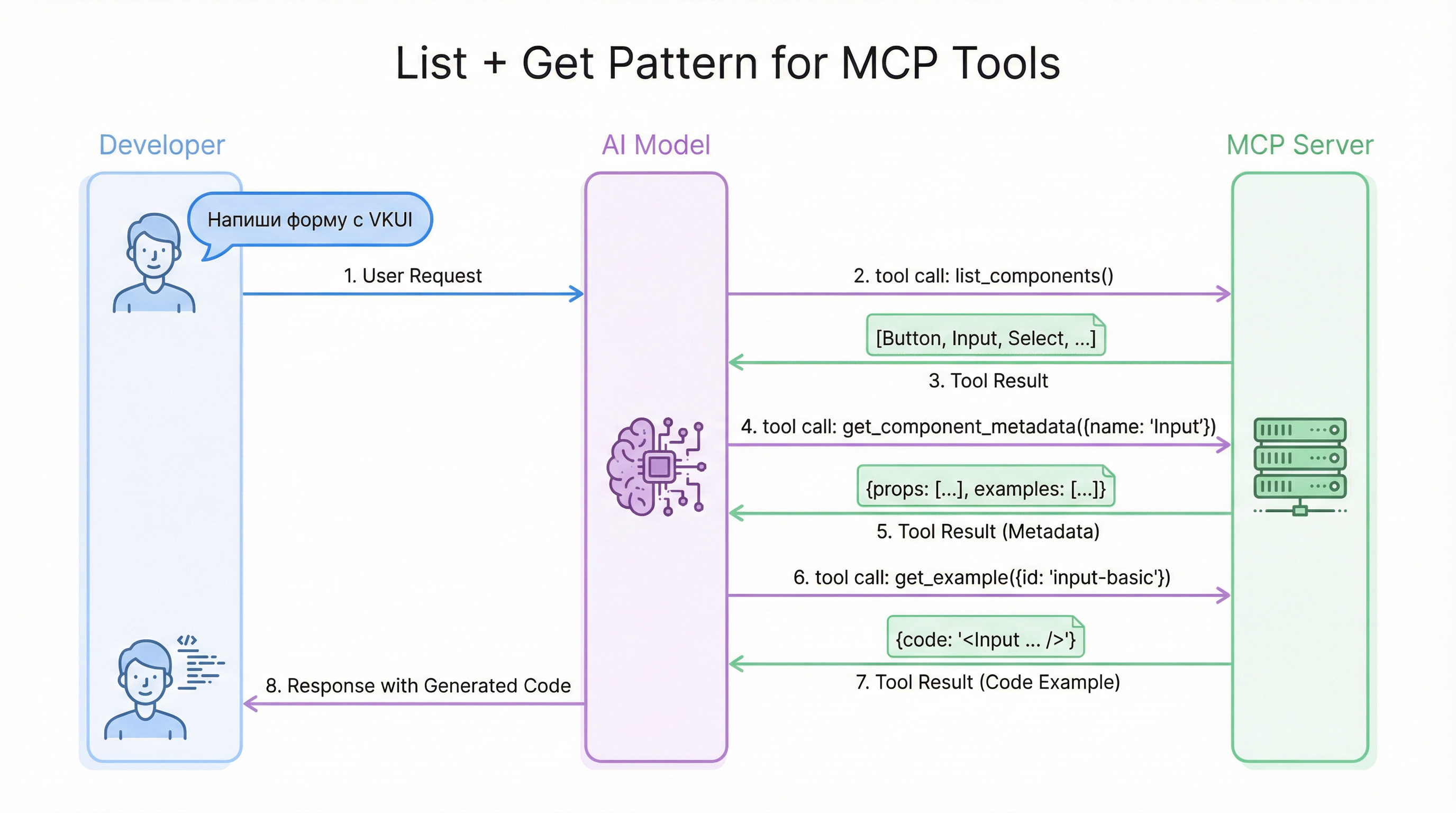
Разработчик работает с AI-ассистентом и просит его написать UI. Модель должна знать, какие компоненты есть в библиотеке и как их правильно использовать. Для этого нужна цепочка:
list_components→ модель видит весь каталог и выбирает подходящий компонентget_component_metadata→ получает пропсы с типами и описаниямиlist_examples+get_example→ смотрит живые примеры из документации
То же самое для хуков: list_hooks → get_hook_metadata.
Этот паттерн — «сначала список, потом детали» — стандартный для MCP. Он экономит токены: модель не загружает всю документацию целиком, а запрашивает только то, что нужно.
Сценарий 2: «Помоги мигрировать на v8»
При обновлении мажорной версии десятки компонентов меняют API. Разработчик хочет, чтобы AI прошёлся по проекту и обновил код. Для этого:
list_migration_targets→ модель видит, какие компоненты и хуки затронутыget_migration_target→ для каждого получает фрагменты кода «до» и «после»
Модель может итеративно пройти по проекту: для каждого файла проверить, используются ли затронутые компоненты, и при необходимости обновить код, опираясь на конкретные примеры миграции.
Сценарий 3: «Дай контекст для разговора»
Иногда нужно не вызывать инструмент, а просто подключить данные как контекст. Для этого есть ресурсы: vkui://component/button даёт карточку компонента Button, vkui://migration/v8 — обзор всех миграций. Клиент может автоматически подгрузить эти данные перед началом разговора.
Принцип: list + get
Все инструменты следуют паттерну list + get: сначала список (лёгкий, с минимумом данных), потом детали по конкретному элементу. Это позволяет не перегружать контекстное окно модели и запрашивать данные точечно.
Способы хранения данных для MCP-сервера
Один из ключевых вопросов при создании MCP-сервера — где хранить данные, которые он отдаёт. Я рассматривал три подхода, каждый из которых имеет свои компромиссы.
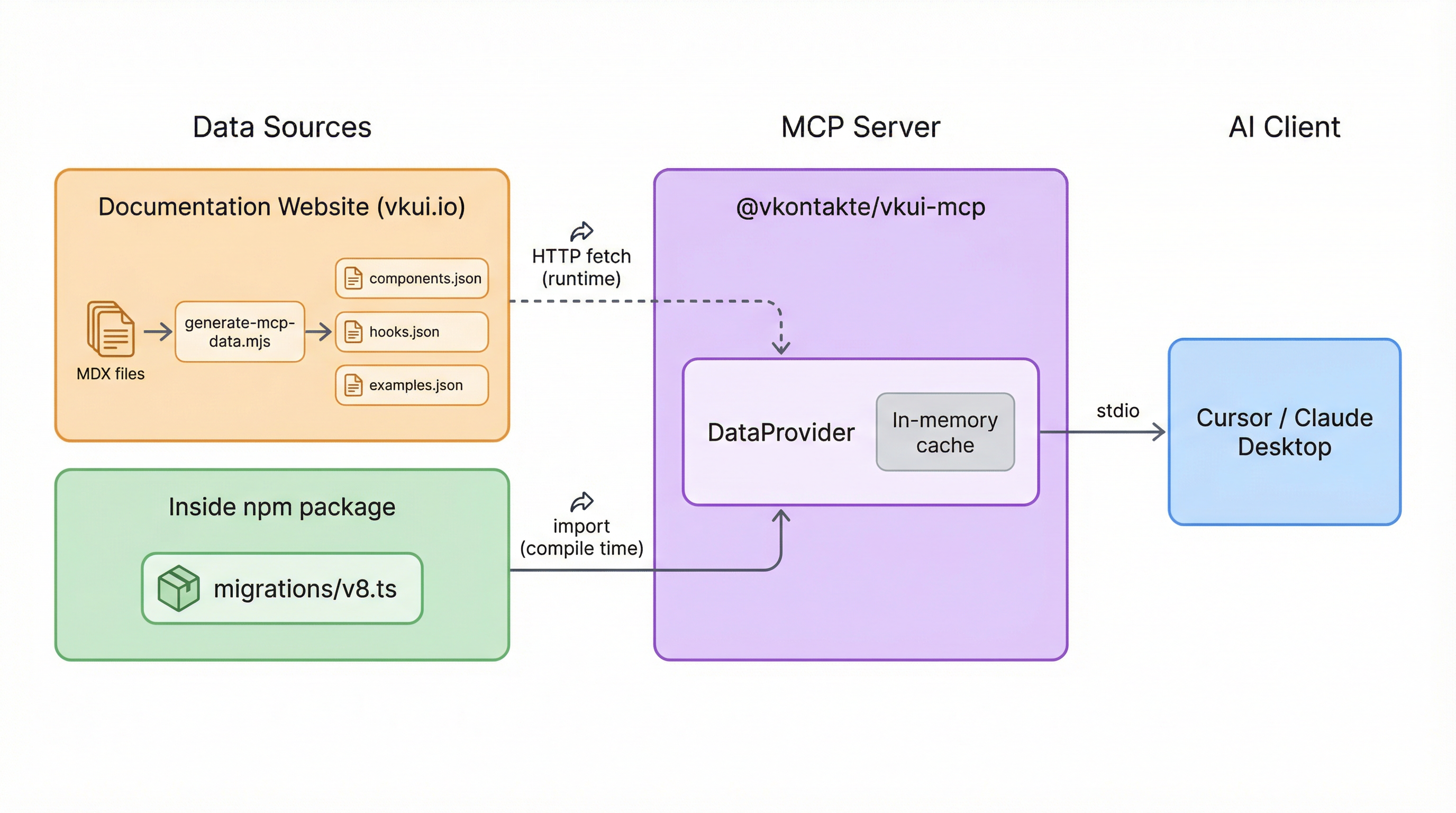
Подход 1: Данные на сайте документации
Это основной подход, выбранный для компонентов, хуков и примеров. При сборке сайта документации запускается скрипт generate-mcp-data.mjs, который:
- Обходит MDX-файлы с документацией компонентов
- Извлекает описания, пропсы (из
docgen.json), примеры кода (из блоковjsxв MDX) - Генерирует JSON-файлы в
public/mcp/— они попадают на сайт как статические файлы
MCP-сервер при запуске загружает эти JSON по HTTP с сайта документации (по умолчанию https://vkui.io). Базовый URL настраивается через переменную окружения VKUI_DOCS_BASE_URL.
async function readJson<T>(relativePath: string): Promise<T> {
const cached = cache.get(relativePath);
if (cached !== undefined) {
return cached as T;
}
const url = new URL(relativePath, baseUrl).toString();
const response = await fetch(url);
if (!response.ok) {
throw new Error(`Не удалось загрузить ${url}: ${response.status}`);
}
const data = await response.json() as T;
cache.set(relativePath, data);
return data;
}
Плюсы:
- Данные всегда актуальны — при деплое новой версии документации MCP-сервер автоматически получает свежие данные без обновления пакета.
- Пакет остаётся лёгким — npm-пакет содержит только код сервера, а не всю документацию.
- Единый источник правды — данные для сайта и для MCP генерируются из одних и тех же MDX-файлов.
- Гибкость — можно указать другой URL (например, локальный сервер документации для разработки).
Минусы:
- Зависимость от сети — при первом запуске нужен интернет. Если сайт документации недоступен, сервер не может работать.
- Латентность — первый запрос к каждому эндпоинту требует HTTP-запроса. Частично решается кешированием в памяти.
- Зависимость от инфраструктуры сайта — если меняется структура URL или формат JSON на сайте, нужно обновлять и сервер, и скрипт генерации.
Подход 2: Отдельное облачное хранилище
Данные можно вынести в отдельный S3-бакет, CDN или другое хранилище, не привязанное к сайту документации.
Плюсы:
- Независимость от сайта — данные живут отдельно, можно обновлять их независимо от деплоя документации.
- Высокая доступность — CDN обеспечивает быструю раздачу и отказоустойчивость.
- Версионирование — можно хранить данные для разных версий библиотеки и переключаться между ними.
Минусы:
- Дополнительная инфраструктура — нужно настраивать и поддерживать отдельное хранилище, CI/CD для его обновления.
- Синхронизация — нужно следить, чтобы данные в хранилище соответствовали актуальной версии документации. Появляется ещё одна точка отказа.
- Стоимость — дополнительные расходы на хостинг и трафик.
Подход 3: Данные внутри пакета
Данные вкомпилированы прямо в npm-пакет — как TypeScript/JS модули или JSON, лежащие в dist/.
Именно этот подход используется для данных по миграции на v8. Миграционные рекомендации — это статический набор фрагментов кода «до» и «после», который не меняется между релизами MCP-сервера.
export const migrationV8: MigrationComponentMap = {
'ActionSheet': {
before: '<ActionSheet\n onClose={() => {}}\n ...',
after: '<ActionSheet\n onClosed={() => {}}\n ...',
},
'Alert': {
before: '<Alert\n onClose={() => setPopout(null)}\n ...',
after: '<Alert\n onClosed={() => setPopout(null)}\n ...',
},
// ...ещё ~30 компонентов и хуков
};
Плюсы:
- Работает офлайн — не нужен интернет, данные доступны сразу после установки пакета.
- Нулевая латентность — данные в памяти, никаких HTTP-запросов.
- Простота — нет внешних зависимостей, нет сети, нет кеша.
- Предсказуемость — версия данных привязана к версии пакета, никаких сюрпризов.
Минусы:
- Обновление требует релиза — чтобы обновить данные, нужно выпустить новую версию пакета. Для часто меняющихся данных (список компонентов, примеры) это создаёт задержку.
- Размер пакета — если вкомпилировать всю документацию (описания, пропсы, сотни примеров), пакет станет тяжёлым.
- Дублирование — данные существуют и в документации, и в пакете. Нужно поддерживать синхронизацию.
Гибридный подход
В итоге я выбрал гибридный подход:
- Компоненты, хуки и примеры загружаются с сайта документации — они часто меняются, и важно, чтобы модель видела актуальные данные без обновления пакета.
- Данные по миграции вкомпилированы в пакет — они статичны для конкретной мажорной версии и не должны меняться после публикации гайда.
Такое разделение даёт баланс: часто обновляемые данные всегда свежие, а стабильные данные работают без зависимости от сети.
Подключение
Подключить сервер в Cursor или другом MCP-клиенте — одна строка в конфиге:
{
"mcpServers": {
"vkui": {
"command": "npx",
"args": ["-y", "@vkontakte/vkui-mcp"]
}
}
}
После этого AI-ассистент получает доступ ко всем инструментам и ресурсам и может использовать их при работе с кодом на VKUI.
Итог
- MCP-сервер — способ дать AI-ассистенту актуальный контекст по библиотеке: компоненты, пропсы, примеры, миграции.
- Набор инструментов строится от сценариев использования и следует паттерну list + get для экономии токенов.
- Хранение данных — гибридный подход: динамические данные загружаются с сайта документации, стабильные данные (миграции) хранятся внутри пакета.
- Подход масштабируется на любую UI-библиотеку или дизайн-систему с обширной документацией.
Исходный код: PR #9512 в VKCOM/VKUI.